

Introduction
So I've had some experience with the whole "serverless" thing over the past few months. A few cloudflare workers, a netlify function here or there to spice up a static site. But a full-on serverless function based project was not something I'd had experience with, until now.
I recently took part in the German government's #wirvsvirus Covid-19 hackathon. My team and I brainstormed for a while, and decided to create an API to provide data to other projects. Of course there were other APIs serving Covid-19 data already, but we wanted to make ours easy to use, with a flashy homepage and easy to digest examples. We even got 500 USD credit from Amazon from the hackathon organisers.
Coffee #1
So we got down to work and in the spirit of a hackathon, decided to work with what we knew best - an EC2 VM running an Express API. We got our source data from @lazd/coronadatascraper which is a great project that serves as a repository for scrapers of all sorts. They scrape health department websites, newspaper, etc. to grab the latest stats and spit out a daily data.json file with the results. In the EC2 architecture we just filtered / mapped this with javascript and returned the results depending on the route requested.
Now after we got the initial MVP working, I decided that this was actually the perfect project to run purely from serverless functions.
So I got started with AWS Lambda directly via their interface and got an MVP up and running relatively quickly. The architecture looked like this:
The coronadatascraper was still executed manually on the server, but instead of just dropping a json file on the filesystem, this was imported into DynamoDB. Each route then queried DyanmoDB for its data, did whatever mapping / filtering / reducing it needed to based on the query parameters, and returned the result.
Technically this worked great, however the performance was almost 2x as slow as the original EC2 based solution.
Coffee #2
So I made another coffee and gave it a think, and decided a cache would be perfect. That way we could save the expensive DB calls only for when it was absolutely necessary. Since these were serverless functions I couldn't just install memcached or redis directly onto the system, but thankfully Redis offers a cloud version of its cache.
So I created a Redis cloud account and setup a database and went on to adjusting the routes. Redis is a simple key value store, so obviously each query, with its various possible parameters obviously had to have a unique key. I decided to give each days data a prefix of the date, 30032020- for example, and tack on the various parameters so each version of the query would have a unique key.
Now the route first checked redis if the key existed, and if so simply returned the data from it, and if not only then query DynamoDB and return that data.
Performance improved immensely. Lambda cold-starts and the first query of a new date / parameter aside, the redis version gave us, on average, a ~100ms improvement over the EC2 time.
I was delighted.
The only problem now was developer experience. AWS is notoriously difficult to manage and work with. I didn't want to manually upload zips of my project every time a change was made.
Coffee #3
So I made another coffee and had another think..
Then I remembered that Netlify Functions are actually nothing more than a nice developer experience wrapper around AWS Lambda functions.
I adjusted the routes a bit for how Netlify expected handlers to be exposed, etc. and made a new Netlify project. For querys with existing keys, it just worked! I quickly discovered a major problem, however.
Without a paid Netlify account you can't integrate with your own AWS services, so I couldn't give Netlify's AWS arn / role access to our DynamoDB instance. Meaning it couldn't query the data when no existing redis key was found. Bummer.
I really liked the developer experience with Netlify, however. They have their own local testing environment you can run - Netlify Dev which allows you to test the functions in your local environment as if they were running on their cloud - and updating production deploys is just as easy as any other Netlify project. I was determined to make this work.
After another coffee or two, I decided to swap the AWS Database with another service which offered a free cloud hosted tier - FaunaDB.
After importing our data into Fauna and adjusting the code to query it instead of Dynamo, queries were once again working without redis keys.
Wait, what just happened?!
I realize this is getting a bit long-winded, so let me summarize what we've done so far. We have 1 initial implementation running on a classic AWS EC2 instance based on a node / express API which simply serves json files off the disk. Then we have another version running on AWS Lambda functions and DynamoDB. Last, but not least, we have a third version running on Netlify Functions with FaunaDB as the datastore.
Testing
It was now time for some performance testing.
After the initial query, all Netlify and Lambda requests were served from the same redis cache. I thought since all three services (the "normal" Lambda functions, the Netlify functions, and Redis itself) were actually running on AWS, the performance should be more or less the same. Boy was I wrong.

The Netlify functions, as you can see in the screenshot above, were often taking over 2! While the EC2 and classic Lambda versions were way more competitive around 200-500ms.
I now had a conundrum - Netlify offered a great developer experience, but the end result had lackluster performance. AWS Lambda had great performance, but was a pain in the ass to develop on.
Coffee #4
Another coffee and a think weren't going to fix this one..
I decided to do some research and sleep on this one. The next morning I found a few different services built around making developing with AWS Lambda functions more palatable. One of which was serverless. It was a bit of a pain to initially setup as it required an additional Cloudformation / Ansible like document to orchestrate the whole thing. But after that was setup and my AWS Account and Github were linked, serverless made the whole experience a breeze.
Unfortunately there was no nice local development tool like Netlify Dev that I could find (if there is and I've overlooked it, please let me know!). But in general the development / deployment / CI/CD experience was fantastic, almost as easy as with Netlify itself. Pushes to Github get their own preview deploy URLs and pushes to master get deployed to the production URL automatically. There is also a really nice monitoring dashboard if you link a serverless cloud account.
Summary
It is obviously still fairly new and the ecosystem is still very fluid, with new services / frameworks / tools coming out constantly. Working with AWS directly is a pain in the ass, but performance is great. Therefore, if you're thinking about whether or not to try your next project as a serverless functions only project, I highly recommend you find a nice framework / tooling solution that wraps AWS, like serverless provides, and you're golden!
Update (03.04.2020):
After having all three implementations run a few days and experimenting around with them all, I decided to kill the Netlify implementation entirely. So we're left with the EC2 Node / Express based server as well as the Lambda serverless implementation.
I've begun migrating more of the routes over to Lambda functions which has been working well. However there is still one significant part of the project I am having trouble migrating to serverless functions, and that is the daily data import. The upstream repo we used offers their output data on the web at coronadatascraper.com/data.json, however, I can never be sure when they update this. I'd like to be able to just fetch this JSON into a function, manipulate it a bit, and push it into DynamoDB.
The other option is to mimic what we've been doing on the server and clone the repo and run the node process manually to get the most up-to-date output data and then push that into Dynamo. I still haven't figured out how to clone a repo, install node dependencies, run a (somewhat long running) node process, and then write the output DynamoDB - all in a Lambda function.
So anyway, other than manually importing the data the Lambda implementation has been running great these last few days!
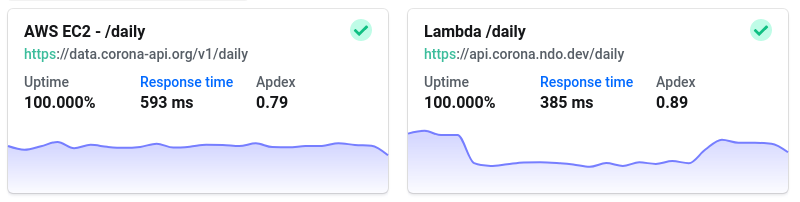
The performance of the Lambda function, with the Redis cache in front of it, is consistently better than the EC2 instance. On average, almost 200ms better! The workflow via serverless also couldn't be any easier, again props to them!